概览
聊天助手和文本生成应用相比,多了对话开场白,下一步问题建议,引用和归属,标注回复等功能。
聊天助手
功能描述
和文本生成应用相比,多了以下功能:
| 功能名称 | 功能含义 |
|---|---|
| 对话开场白 | - |
| 下一步问题建议 | 回答结束后系统会给出 3 个建议 |
| 引用和归属 | 显示引用或归属的知识库文档信息 |
| 标注回复 | 可以将回复进行标注。或者预设标注信息,当问题匹配到标注信息时,则使用预设的信息进行回答。 |
接口信息
接口 console/api/apps/xxx/chat-messages
在聊天助手中,app_model.mode 是 CHAT,所以回调用 ChatAppGenerator().generate 方法
流程详解
- ChatAppGenerator().generate 中,先获取 conversation
- 然后根据 app_model 和 conversation 获取 app model config, 如果是 debug 模式,则允许用户传递的 model config 覆盖 据 app_model 和 conversation 查询出来的
- 解析文件得到 file_objs
- 转换为 app config
- 初始化 application generate entity
- 初始化 generate records
- 初始化 queue manager
- 启动线程,调用 _generate_worker 方法
- 判断 token 数量是否足够
- 重新组织 prompt message
- 进行敏感词检测
- 标注回复
- 填写来自外部数据工具的变量输入,获取上下文信息
- 再次重新组织 prompt message
- 再次敏感词检测
- 加载工具变量
- 初始化模型实例,调用大模型
- 得到 response,将 response 转换后返回出去
可以看出大部分的步骤和文本生成式应用是一致的。相同的部分包括使用消息队列传输消息,知识库上下文召回,敏感词检测,判断 token 数量是否足够等。
标注回复是聊天助手中特有的,详细信息如下:
查询标注回复
标注回复是可以添加的,由一个问题和一个答案组成,当用户的问题和标注回复中的问题一致时,那么就返回指定的内容。去向量数据库中查询的时候,是使用用户提出的问题去查询,如果项目相似度分数 > score_threshold。则取出这个 Document 的 annotation_id,然后获取到这个 annotation 进行返回,上述返回后,就往队列里面塞一条消息,后面就不继续往后执行了。
添加标注回复
添加标注回复时,调用 /console/api/apps/xxx/annotations 接口,会往 MessageAnnotation 表中添加记录。并调用 add_annotation_to_index_task异步方法,异步方法中创建的 Document 的内容为标记回复的问题,元数据中关联了 annotation_id
1 | document = Document( |
下一步问题建议也是文本生成式应用没有的,当启用改功能后,前端会发起一个新的请求,请求地址是 /console/api/apps/xxx/chat-messages/xxx/suggested-questions 用于获取下一步的问题和建议。
此时会获取本轮会话的3条历史记录,最多3000个token,最后组织好 prompt 给到大模型,让大模型根据历史给出相对应的下一步的问题和建议。prompt 如下:
1 | ... |
总结
聊天助手是进一步在文本生成式应用上构建的,大部分流程都相同。
Q:如果 prompt 的 token 过长,怎么处理?
A:当单纯的 prompt(不包含上下文和历史)超过长度时,服务端会抛出错误
1 | rest_tokens = model_context_tokens - max_tokens - prompt_tokens |
Q:如果 prompt 的 token 不过长,但是加上上下文之后过长怎么处理?
A:并不会提示异常。只会更新在内存中的 model_config.parameters[“max_tokens”] 的值为 max(model_context_tokens - prompt_tokens, 16)。但如果超出大模型的限制,大模型接口会提示异常。
1 | if prompt_tokens + max_tokens > model_context_tokens: |

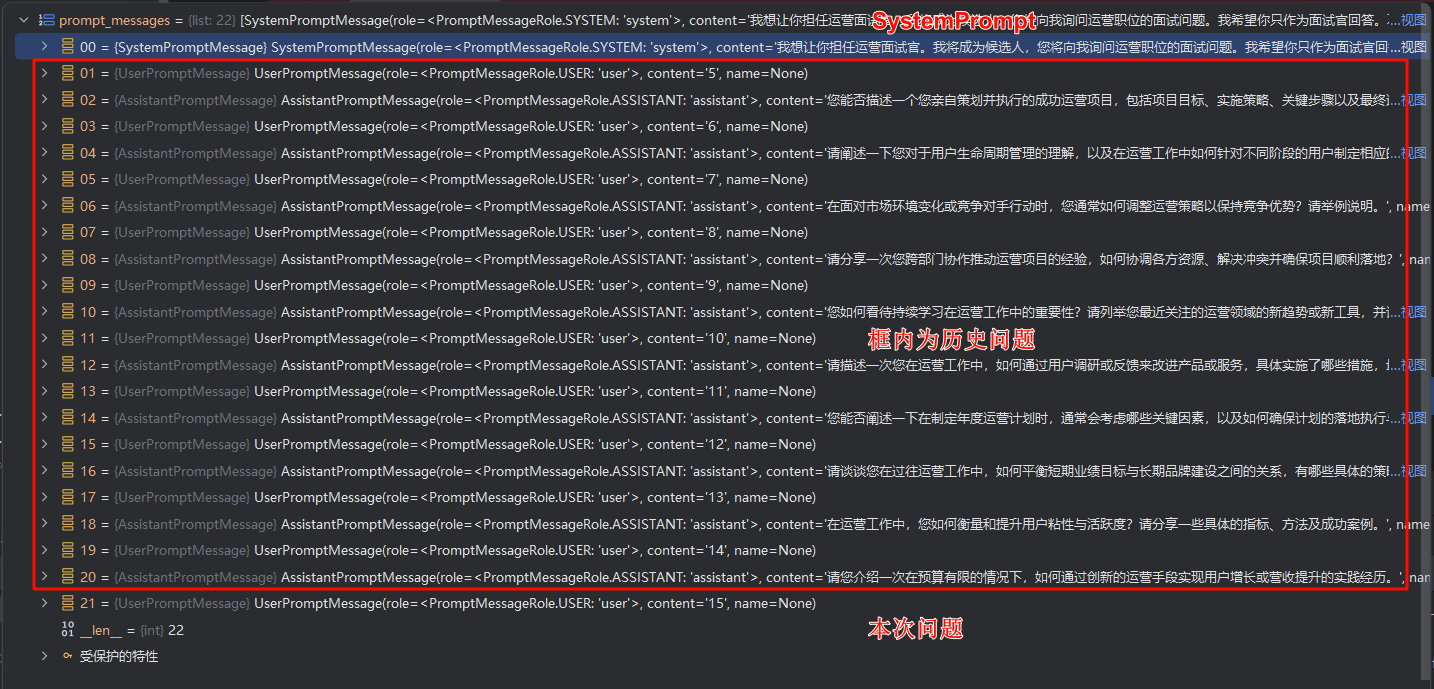
Q:最多可以携带几轮历史会话?
A:最多携带10轮历史会话,总共 22 条消息(1条 SystemPrompt + 20 条历史会话 + 1 条本轮问题)
1 | def get_history_prompt_messages(self, max_token_limit: int = 2000, message_limit: int = 10) -> list[PromptMessage]: |